Tag 9 : Suchmaschinen und Discovery-Systeme 2/2
Themen: Suchmaschine/Suchindex, Solr, Datenintegration, Discovery-Systeme
In dieser Vorlesung widmeten wir uns der Suchmaschine (bzw. dem Suchindex) Solr. Solr ist die Basis für das Discovery-System VuFind und für die “Hintergrundarbeit” gedacht. Die integrierte Suchoberfläche von Solr ist nur für Demo-Zwecke gedacht. Tipp: auch kommerzielle Lösungen wie z.B Ex Libris Primo basieren auf Solr. Somit ist Solr eine weit verbreitete Suchmaschine.
Funktion von Suchmaschinen am Beispiel von Solr
Unterschied zwischen einem Suchindex (Solr) und einer Datenbank (MySQL)?
Einen Unterschied findet mal beispielsweise in der Struktur. Die Inhalte in MySQL sind stärker strukturiert (relationale Datensätze). Zudem macht eine Datenbank einen reinen “Glyphenvergleich” (macht genau das was ich eingegeben habe). Der Suchindex wiederum macht eine lexikalische Suche. Das heisst: es kann in Textpassagen nach einzelnen Begriffen gesucht werden. Es ist also eine Volltextsuche möglich. Die Stärke von Solr liegt, im Gegensatz zu MySQL, klar in den Retrievalmöglichkeiten. Abschliessend soll erwähnt werden, dass ein Suchindex eher statische Daten abbildet, während in einer Datenbank veränderliche Daten zu finden sind (siehe dazu CRUD). Somit eignet sich Solr um in einem grossen Datenbestand gezielt einzelne Datensätze zu finden (Retrieval, Suche). Eine Datenbank eignet sich wiederum für die konsistente und langfristige Datenablage.
Übung: Suche in VuFind vs. Suche in Solr
Für die Übung wurde mit dem Suchbegriff “psychology” eine Suche in VuFind und Solr durchgeführt. Es wurde beobachtet inwiefern sich die Logdateien im Terminal unterscheiden.
Ich startete mit der Suche in VuFind. Rechts in der Logdatei wird angezeigt wie die verschiedenen Felder gewertet werden für das Ranking.
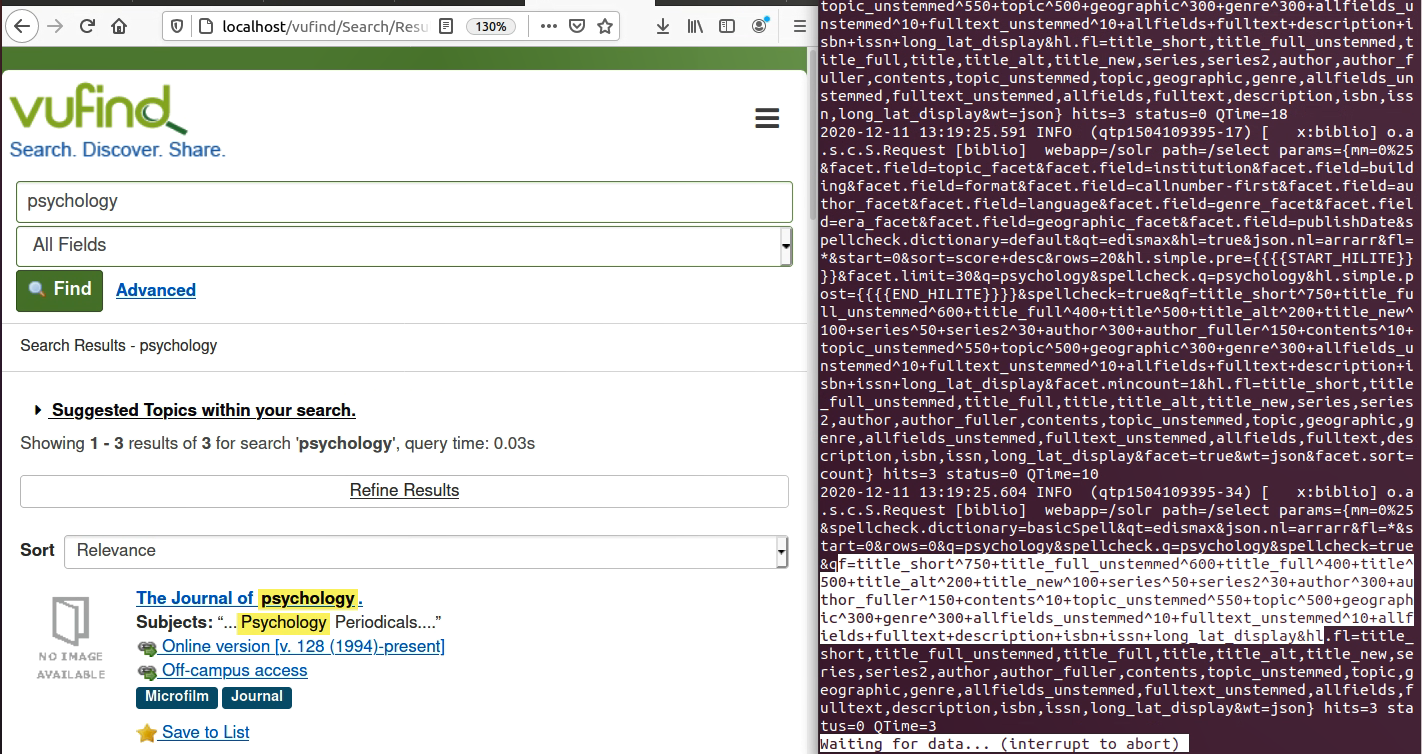
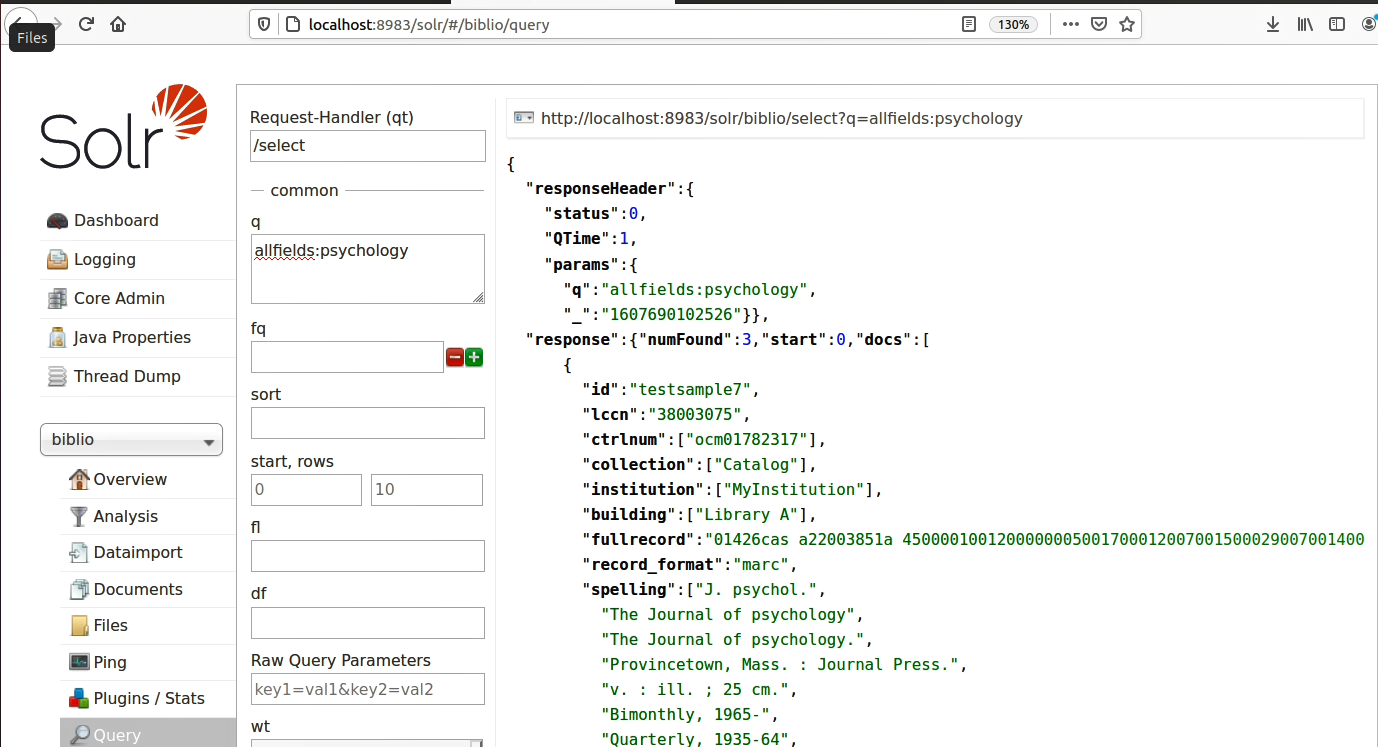
Bei der Suche in Solr zeigte sich, dass die Logdatei viel kürzer war (weil kein Ranking durchgeführt wurde). Nachfolgend ein Eindruck von der Suchoberfläche von Solr. Die Logdatei wird hier nicht abgebildet.
Übung zur Datenintegration
Ziel: Import der mit MarcEdit und OpenRefine konvertierten Daten (Format MARCXML) aus Koha, ArchivesSpace, DSpace und DOAJ in VuFind.
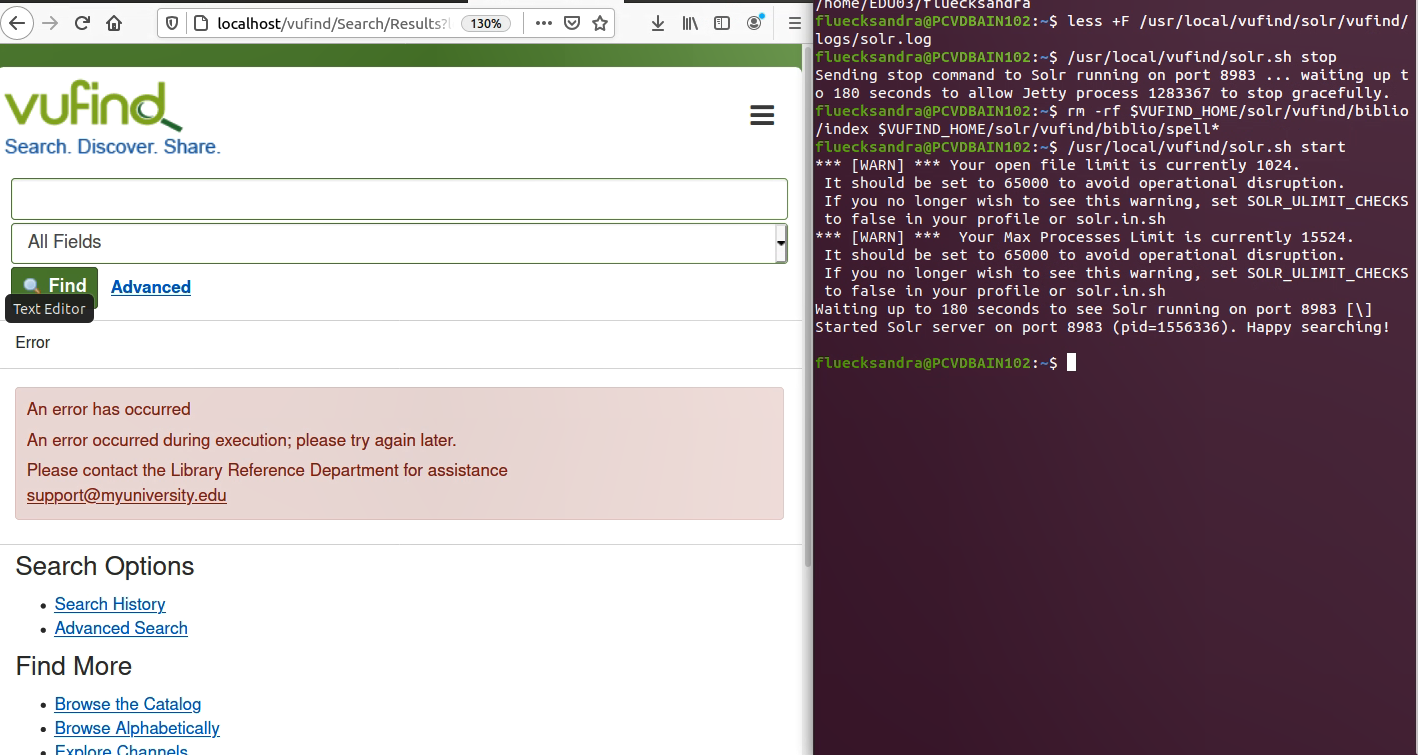
Dafür wurden zunächst die bereits geladenen Testdaten über das Terminal wieder gelöscht. Im Bild ist ersichtlich, dass die Löschung funktioniert hat. Es werden keine Datensätze mehr geladen, wenn auf “Find” geklickt wird.
Nach dem Entpacken der Beispieldaten wurden zunächst die Daten von Koha importiert. Diese Daten konnten problemlos importiert werden. Bei ArchivesSpace und Dspace funktionierte der Import jedoch nicht. Gemäss Terminal wurden die Dateien gelesen und indexiert aber nicht importiert:

Der Terminal zeigte bei jedem Versuch ein Problem mit einer “fehlenden ID” an.

Problem
Nun zeigte sich folgendes Problem: bei Solr braucht es immer einen eindeutigen Identifier. Dies ist ein verpflichtendes Feld. VuFind erwartet, dass das Feld 001 belegt ist. Aus MARC-Daten wird das Feld 001 Control Number als ID verwendet. Der Import funktioniert nicht, wenn dieses Feld 001 nicht im XML-File vorhanden ist. Bei den Daten aus ArchivesSpace und DSpace ist das Feld offensichtlich nicht belegt.
Lösung
Bei den Daten aus ArchivesSpace und DSpace dieses Feld eintragen. Das leuchtet mir ein.
Marktüberblick Discovery-Systeme
Schliesslich auch hier noch ein kurzer Marktüberblick: Primo ist Marktführer bei wissenschaftlichen Bibliotheken. Summon gehört wie Primo auch zu ProQuest und ist stark verbreitet. Discovery Systeme für öffentliche Bibliotheken und Schulbibliotheken sind in der Regel ganz andere.
Diese Übersicht gibt einen guten Überblick über die verschiedenen Systeme.