Tag 7 - Zusatzartikel zur Aufgabe Anreicherung mit lobid-gnd
Dieser Beitrag berichtet über die Aufgabe Anreicherung mit lobid-gnd, die selbständig gelöst werden sollte.
Aufgabe 1
Die Autorennamen in den DOAJ-Daten sollen mit zusätzliche Informationen (z.B. GND-Nummer und Geburtsjahr) aus lobid-gnd angereichert werden. Die allgemeinen Anleitung im Blog von lobid-gnd unterstützt uns bei der Aufgabe.
Vorgehen
Dafür ist zunächst ein Abgleich (Reconciliation genannt) nötig. Reconciliation bedeutet genauer gesagt, dass Strings mit Identifiern von Entitäten in Datenbanken wie GND, Wikidata etc. abgeglichen werden. Nur so können schliesslich zusätzlich Daten bei den richtigen Zellen hinzugefügt werden.
Meine Ausgangslage für diese Aufgabe: Autoren sind gesplittet (in verschiedene Zellen aufgeteilt). Überlegung: ansonsten können die Geburtsdaten nicht genau 1 Person zugeordnet werden.
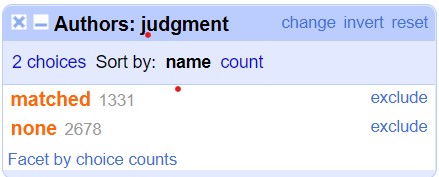
Zunächst werden die Text Strings in der Spalte “Authors” mit den GND-Einträgen abgeglichen. Dabei wird vorgegangen wie in der allgemeinen Anleitung im Blog von lobid-gnd. Die erste Frage ergibt sich hier (siehe folgendes Bild). Ausgewählt wird wie in der Anleitung “Individualisierte Person”. Ich frage mich: Wann wird “Normdatenressource” gewählt?

Weitere Felder für den Abgleich werden nicht ausgewählt, weil keine weitere personenspezifische Angaben (wie z.B der Beruf) in der Tabelle vorliegen. Das Resultat: nur 1331 Matches.
Es gäbe nun die Möglichkeit bei jeder Zelle jeweils automatisch den “besten Kandidaten” auszuwählen.
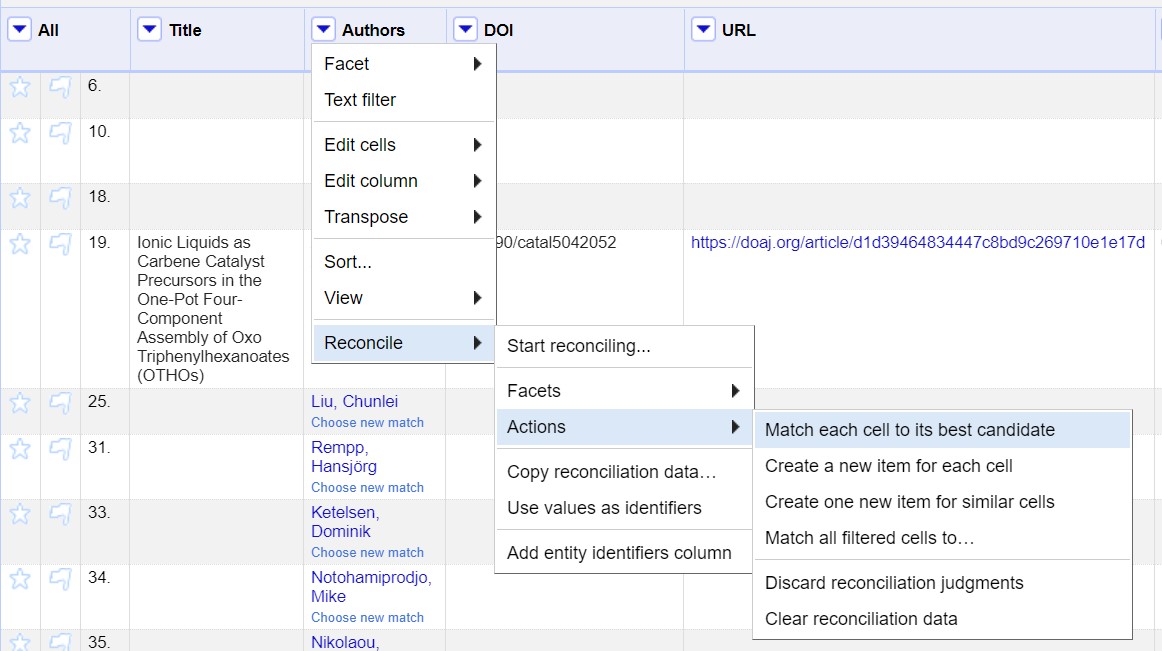
Dies wird kurz getestet aber sofort wieder rückgängig gemacht. Denn aus Flavia Pennini wird beispielsweise Alessandra Pennini. Da nur mit dem Namen abgeglichen wurde, ist es eher unwahrscheinlich, dass das stimmt. Offenbar gibt es einfach keinen GND-Eintrag für den Namen Flavia Pennini.
Schliesslich werden neue Spalten mit den Angaben “Geburtsdatum” und “GND-Nummer” hinzugefügt.
Generell ist es sicherlich gefährlich zusätzliche Informationen wie Geburtsdatum und GND-Nummer einer Person zuzuweisen, nur weil der Namen übereinstimmt. Die Wahrscheinlichkeit ist sehr hoch, dass diese Daten einer falschen Person zugeordnet werden.
Aufgabe 2
Das Template soll nun erweitert - und die Daten in XML exportiert werden. Dazu der Hinweis: Im MARC21 Format gehören weiterführende Informationen zu Autoren in Unterfelder der Felder 100 und 700. Siehe Beispiele in der Formatdokumentation.
Vorgehen
Über “Export” - “Templating” wird das Template nun in XML exportiert. Das Row Template der Dozierenden (siehe Tag 7, Aufgabe 1) soll entsprechend angepasst werden, damit auch die Geburtsdaten und die GND-Nummer exportiert werden.
Zunächst werde die gesplitteten Zellen wieder “gejoined”, weil die Autoren in der gleichen Zelle sein müssen (getrennt durch die Pipe), damit die Regel im Row Template funktioniert und der jeweils erste Autor ins Feld 100 und die anderen Autoren ins Feld 700 kommen. Anschliessend werden im Template bei Feld 100 und 700 folgende Änderungen vorgenommen, damit das Geburtsdatum und die GND-Nummer in das richtige Unterfeld ausgegeben werden:
Feld 100
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
<subfield code="d">{{cells['Geburtsdatum'].value.split('|')[0].escape('xml')}}</subfield>
<subfield code="0">{{cells['GND-Nummer'].value.split('|')[0].escape('xml')}}</subfield>
</datafield>
Feld 700
Ich habe selber keine funktionierende Regel formulieren können (weiter unten wird eine mögliche Lösung vorgeschlagen, die die Dozierenden in der nächsten Vorlesung präsentierten).
Folgendes Problem wurde erkannt
Wenn die Autoren wieder gejoined werden, dann werden die angereicherten Daten nicht eindeutig den Autoren zugeordnet. Beispiel:
Marie Emmanuelle (vor Join) - Geburtsdaten sind eindeutig der Person zugeordnet:

Marie Emmanuelle (nach Join) - Geburtsdaten sind nicht mehr sichtbar der Person zugeordnet:
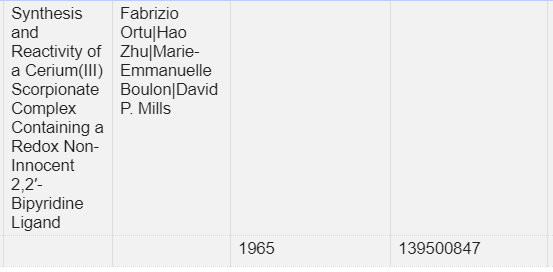
Die Geburtsdaten von Marie Emmanuelle (nach Join - exportiert in XML) werden getrennt von der Person ausgegeben:

Mögliche Lösung für Aufgabe 2 - Vorschlag der Dozierenden
Damit die Daten den einzelnen Autoren eindeutig zugeordnet werden:
In den neuen Spalten Geburtsdatum und GND-Nummer zunächst einen Platzhalter (z.B. $) in leere Zellen einfügen:
- Facet > Customized facets > Facet by blank > true
- Edit cells… > Transform > ‘$’
Anschließend Spalten Authors, Geburtsdatum und GND-Nummer zusammenführen:
- Edit cells… > Join multi-valued cells
Im folgenden Unterricht wurde dann folgende Lösung für Feld 700 vorgeschlagen:
{{
forEachIndex(cells['Authors'].value.split('|').slice(1), i, v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>'
+ forNonBlank(cells['GND-Nummer'].value.split('|').slice(1)[i].replace('$',''), gnd ,'
<subfield code="0">' + gnd.escape('xml') + '</subfield>', '')
+ forNonBlank(cells['Geburtsdatum'].value.split('|').slice(1)[i].replace('$',''), geburt ,'
<subfield code="d">' + geburt.escape('xml') + '</subfield>', '')
+ '</datafield>')
}}
Anmerkungen:
- Die Funktion forEachIndex() führt im Vergleich zu forEach() zusätzlich den Index in eine Variable (hier:
i). Damit lassen sich zugehörige Daten adressieren, die den gleichen Index haben. - Ein Teil eines Arrays lässt sich addressieren über den Index in eckigen Klammern. Beispiel:
[0]für das erste Element. Hier wird mit[i]die Zahl aus der Variableieingefügt. - Die Funktion
replace('$','')entfernt den Platzhalter. - Die Funktion forNonBlank() hat 4 Parameter.
- Der Ausdruck im ersten Parameter wird in eine Variable geschrieben.
- Der Name der Variable wird im zweiten Parameter definiert.
- Im dritten Parameter wird definiert, was ausgegeben werden soll, wenn die Variable etwas beinhaltet (nicht leer ist).
- Im vierten Parameter wird definiert, was ausgebenen werden soll, wenn die Variable leer ist (hier:
''= ein leerer String).
- An dieser komplexen Lösung wird deutlich, wie umständlich die Verarbeitung von hierarchischen Strukturen in Tabellenform sein kann.