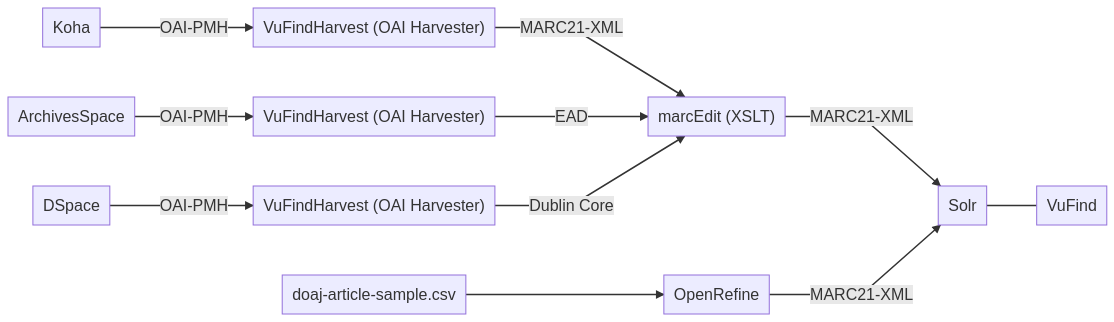
Tag 7 : Metadaten modellieren und Schnittstellen nutzen 2/2
Themen: OpenRefine, Datentransformation, CSV, MARCXML
In dieser Vorlesung befassten wir uns erneut mit dem Thema Metadaten modellieren und Schnittstellen nutzen. Heute ging es darum Metadaten mit der Software OpenRefine von CSV nach MARCXML zu transformieren. Als Vorbereitung auf diese Lektion haben wir OpenRefine installiert und die Lehrmaterialien von Library Carpentry zu OpenRefine durchgearbeitet. In dieser Vorlesung machten wir nun weitere Übungen mit den Beispieldaten, die wir bereits für den Vorbereitungsauftrag in OpenRefine geladen hatten (siehe doaj-article-sample.csv im Schaubild).
Einführung OpenRefine
Zunächst starteten wir mit einer Einführung in die Software OpenRefine. Der Claim der Software lautet wie folgt:
“A free, open source, powerful tool for working with messy data”
Für OpenRefine gibt es viele verschiedene Einsatzbereiche. Die Software wird vorwiegend für die Bereinigung, Konvertierung, Anreicherung und Analyse von Daten verwendet. Sie wird lokal installiert und über den Browser bedient. OpenRefine ist keine bibliotheksspezifische Software, wird aber dennoch sehr oft im Bibliotheksbereich verwendet. Die Software ist besonders geeignet für tabellarische Daten (CSV, TSV, XLS, XLSX etc.). Auch einfaches XML (z.B MARCXML) oder JSON sei mit etwas Übung noch relativ einfach zu modellieren.
Konkrete Einsatzmöglichkeiten von OpenRefine sind:
- Exploration von Datenlieferungen (z.B gelieferte Verlagsdaten prüfen)
- Vereinheitlichung und Bereinigung von Daten
- Abgleich mit Normdaten (nennt man auch “Reconciliation”) aus der GND oder VIAF
Interessant ist, dass die Firma metaweb, welche die Software entwickelte, zunächst von Google gekauft - und der Code dann aber schliesslich an die OpenSource-Community weitergegeben wurde. Ganz zu Beginn hiess die Software Freebase Gridworks, anschliessend Google Refine und zum Schluss OpenRefine. Quelle: OpenRefine (Wikipedia).
Ein interessanter Hinweis bezüglich Alma: Es gibt ein ALMA Refine. Ex libris hat die Funktionalitäten von der OS-Software übernommen.
Übung: CSV nach MARCXML mit OpenRefine
Für die Transformation nutzten wir die Funktion “Templating Exporter”.
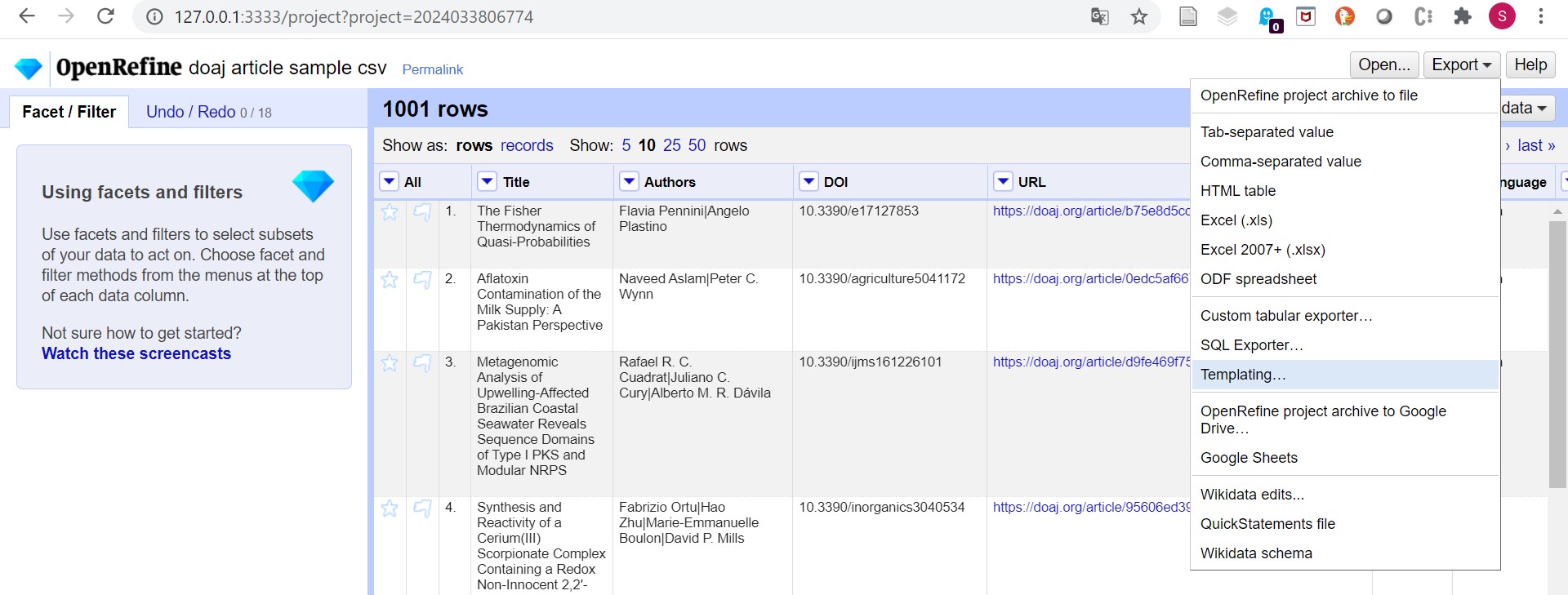
Aufgabe 1: Reverse Engineering
Zunächst ging es darum die Ausgangsdaten mit dem Ergebnis zu Vergleichen und die Transformationen in den verschiedenen Feldern zu beschreiben. Dafür nutzten wir eine Vorlage der Dozierenden. Das Row Template der Dozierenden sieht folgendermassen aus:
<record>
<leader> nab a22 uu 4500</leader>
<controlfield tag="001">{{cells['URL'].value.replace('https://doaj.org/article/','').escape('xml')}}</controlfield>
<datafield tag="022" ind1=" " ind2=" ">
<subfield code="a">{{cells['ISSNs'].value.escape('xml')}}</subfield>
</datafield>
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
</datafield>
<datafield tag="245" ind1="0" ind2="0">
<subfield code="a">{{cells["Title"].value.escape('xml')}}</subfield>
</datafield>{{
forEach(cells['Authors'].value.split('|').slice(1), v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
</datafield>')
}}
</record>
Links wurde diese Vorlage eingegeben und rechts werden die Daten entsprechend ausgegeben.
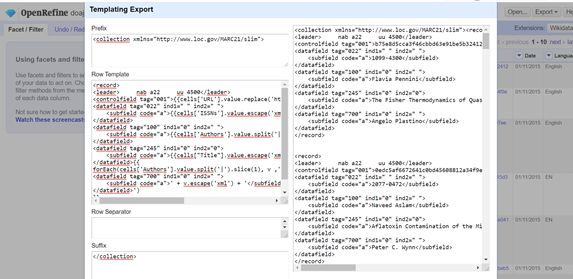
Folgende Erkenntnisse wurde aus dem Vergleich gezogen:
- Leader: ist hart kodiert (wird rechts genau so übernommen wie links vorgegeben)
- 001: Der erste Teil der URL wird mit der einfachen replace-Funktion ersetzt durch “ “ (-> nichts) und somit nicht ausgegeben. Das ist praktisch, weil der erste Teil der URL sowieso überall gleich wäre.
- 022: Die ISSN wird ganz einfach ausgelesen
- 100: Nur der erste Autor wird ausgegeben (Feld 100 ist in MARC nur für die Haupteintragung vorgesehen). Die Autoren werden gesplittet über die Pipe. Nach dem Splitten sind alle Autoren in einer Array. Über die [0] wird das erste Element des Arrays angesteuert und ausgegeben.
- 245: Der Titel wird unverändert ausgegeben (durch den Befehl .escape(“xml”) wird dafür gesorgt, dass keine unerlaubte Zeichen im Titel sind)
- 700: Alle Autor’innen ausser der 1. Person werden durch die Schleifenfunktion forEach nacheinander ausgegeben. Zunächst werden die Autoren aufgesplittet und in ein Array gespeichert. Über den Befehl slice wird das vorderste Element (1) abgeschnitten. Die Autoren werden in der Variable v gespeichert und dann im Element 700, Unterfeld a ausgegeben.
Aufgabe 2: Eigene Regeln erstellen
Nun sollten wir in Gruppen eine eigene geeignete Regel erstellen, um die gewünschten Daten der gewählten Spalten in MARC21 zu transformieren. Dafür mussten wir zunächst herausfinden, welche Spalte aus den DOAJ-Daten welchen Feldern und Unterfeldern in MARC21 entsprechen. Wir haben uns für die Spalte “Publisher” entschieden. Die Daten aus dieser Spalte gaben wir mit folgender Regel in Feld 260, Unterfeld b aus.
<datafield tag="264" ind1=" " ind2=" ">
<subfield code="b">{{cells["Publisher"].value.escape('xml')}}
</datafield>
Problem mit leeren Zellen
Es ist möglich, dass Zellen leere Werten enthalten. Es sollten Regeln geschaffen werden, was passieren soll, wenn die Zelle leer ist. Es gibt 2 Arten von leeren Zellen. Es kann “gar nichts” drin sein (-> leerer String) oder es kann eine technische “null” sein.
Wenn die Spalten leere Zellen enthalten, dann sollte die Funktion forNonBlank() verwendet werden. Mit dieser Funktion kann dafür gesorgt werden, dass, je nach dem, ob Werte in der Zelle vorhanden sind oder eben nicht, bestimmte Daten ausgegeben werden sollen.
Beispiel:
{{
forNonBlank(
cells['DOI'].value,
v,
'<datafield tag="024" ind1="7" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
<subfield code="2">doi</subfield>
</datafield>',
''
)
}}